Correlation is a measure of the relationship between two variables. The correlation can range from -1 indicating a “perfect” negative relationship to 1 indicating a “perfect” positive relationship. A correlation of 0 indicates no relationship. Figure 4.1 depicts scatter plots with various correlations.
Figure 4.1: Scatterplots representing correlations from -1 to 1.
For a population, the correlation is defined as the ratio of the covariance to the product of the standard deviations, and is typically denoted using the Greek letter rho (\(\rho\)), is defined as:
The standard deviation (\(\sigma\)) is equal to the square root of the variance (\(\sigma = \sqrt{\frac{\Sigma(x_i - \bar{x})^2}{n - 1}}\)) which is covered in detail in Section 3.1. What is new here is the covariance. Like variance, we are interested in deviations from the mean except now in two dimensions. The formula for the covariance is:
Let’s break down Equation 4.2 visually. The following R code generates a data frame with two variables, x and y, with means of 20 and 40 and standard deviatiosn of 2 and 3, respectively. The population correlation is 0.8 (note that the sample will likely have a slightly different correlation).
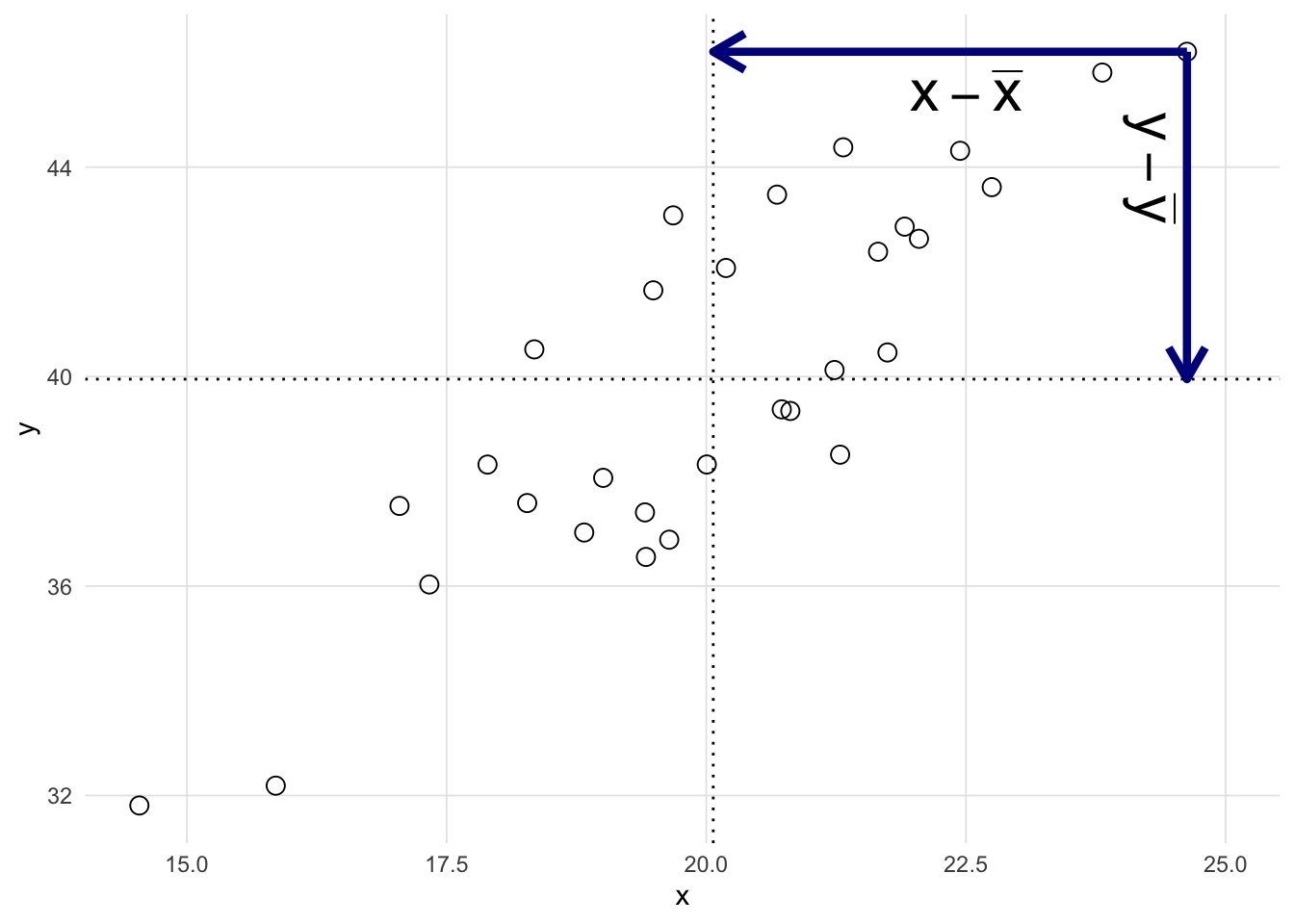
The numerator of the covariance equation included the product of the deviation from the mean in the x direction (i.e. \(x_i - \bar{x}\)) and the y direction (i.e. \(y_i - \bar{y}\)). Figure 4.2 depicts the scatter plot with all 30 observations, the mean of x and y as dashed lines, and the deviations for one observation represented by blue arrows.
Show the code
deviation_to_plot <-23regression_vis(df,plot_x_mean =TRUE,plot_y_mean =TRUE,plot_positive_cross_products =FALSE,plot_negative_cross_products =FALSE,plot_x_deviations = deviation_to_plot,plot_y_deviations = deviation_to_plot) +annotate('text', x =22.5, y =46.2,label =bquote("x - bar(x)"), parse =TRUE, vjust =1.5, size =8) +annotate('text', x =25.0, y =44,label =bquote("y - bar(y)"), parse =TRUE, vjust =2, size =8, angle =-90)
Figure 4.2: Scatter plot showing the deviations for x and y.
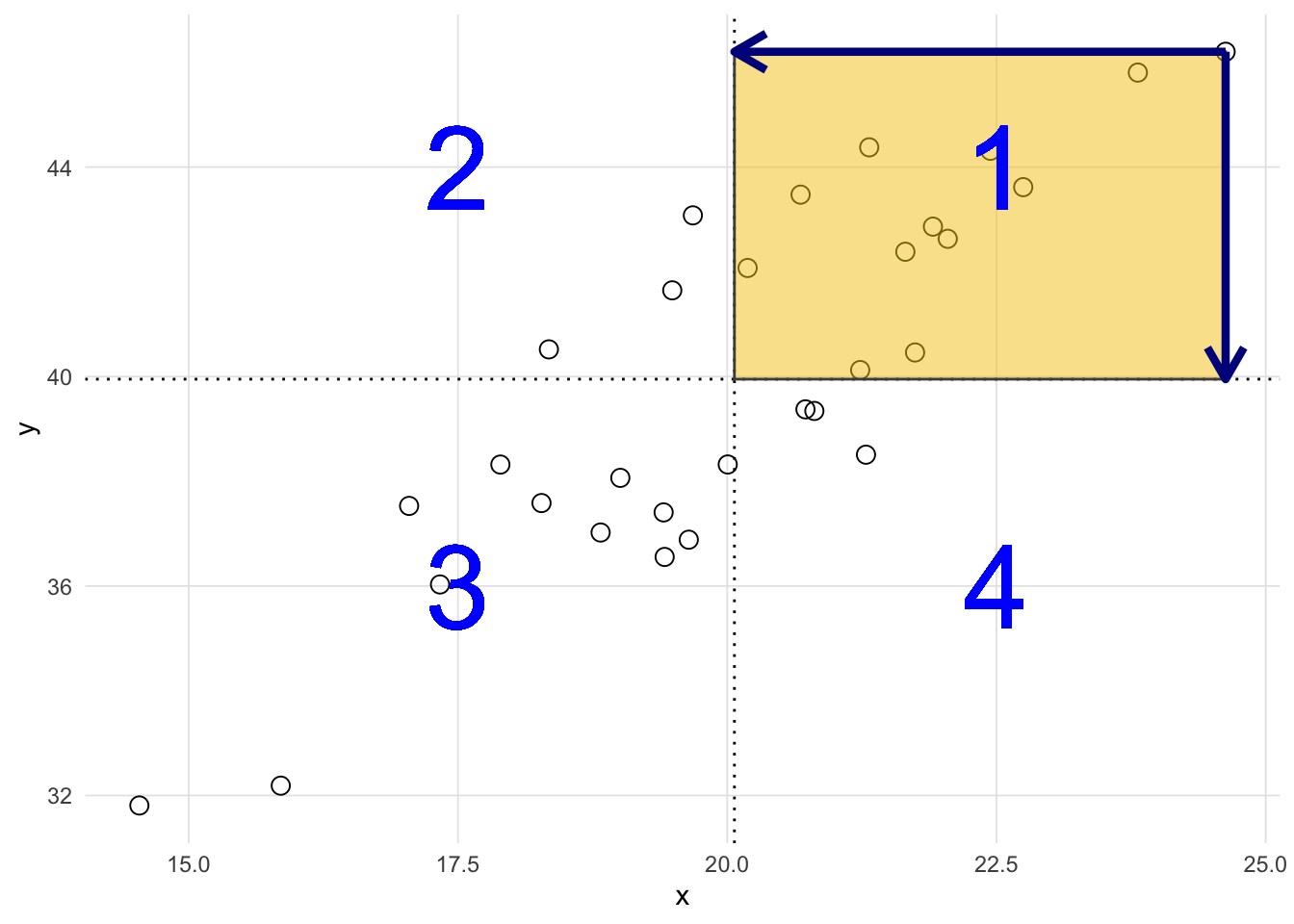
Hence, for each observation (i) in our data frame the numerator is summing the area of a rectangle (see Figure 4.3 for the one observation in yellow). When we calculate variances we square the deviation which as a result ensures that all the values being summed are positive. However, for covariance this is not the case. The numbers in Figure 4.3 correspond to the four quadrants of the plot. For points that fall in quadrants 1 and 3, the cross products (i.e. \((x_i - \bar{x})(y_i - \bar{y}\)) will be positive. For points that fall in quadrants 2 and 4 however, the cross products will be negative.
Show the code
regression_vis(df,plot_x_mean =TRUE,plot_y_mean =TRUE,plot_positive_cross_products =FALSE,plot_negative_cross_products =FALSE,plot_cross_product = deviation_to_plot,plot_x_deviations = deviation_to_plot,plot_y_deviations = deviation_to_plot,cross_product_alpha =0.5) +geom_text(label ='1', x =22.5, y =44, color ='blue', size =16) +geom_text(label ='2', x =17.5, y =44, color ='blue', size =16) +geom_text(label ='3', x =17.5, y =36, color ='blue', size =16) +geom_text(label ='4', x =22.5, y =36, color ='blue', size =16)
Figure 4.3: Scatter plot showing the deviations for x and y with the cross product represented as the area of the yellow rectangle.
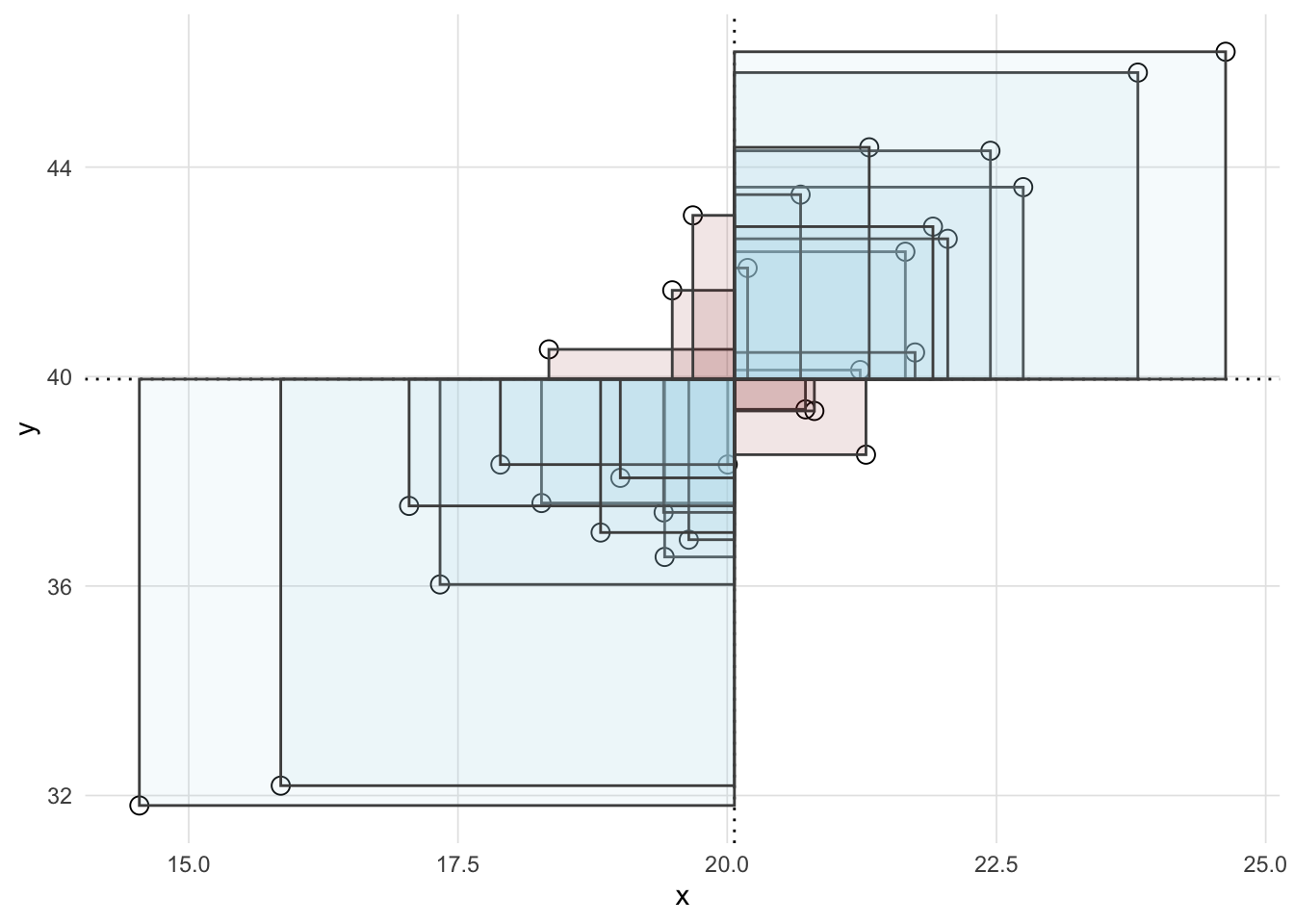
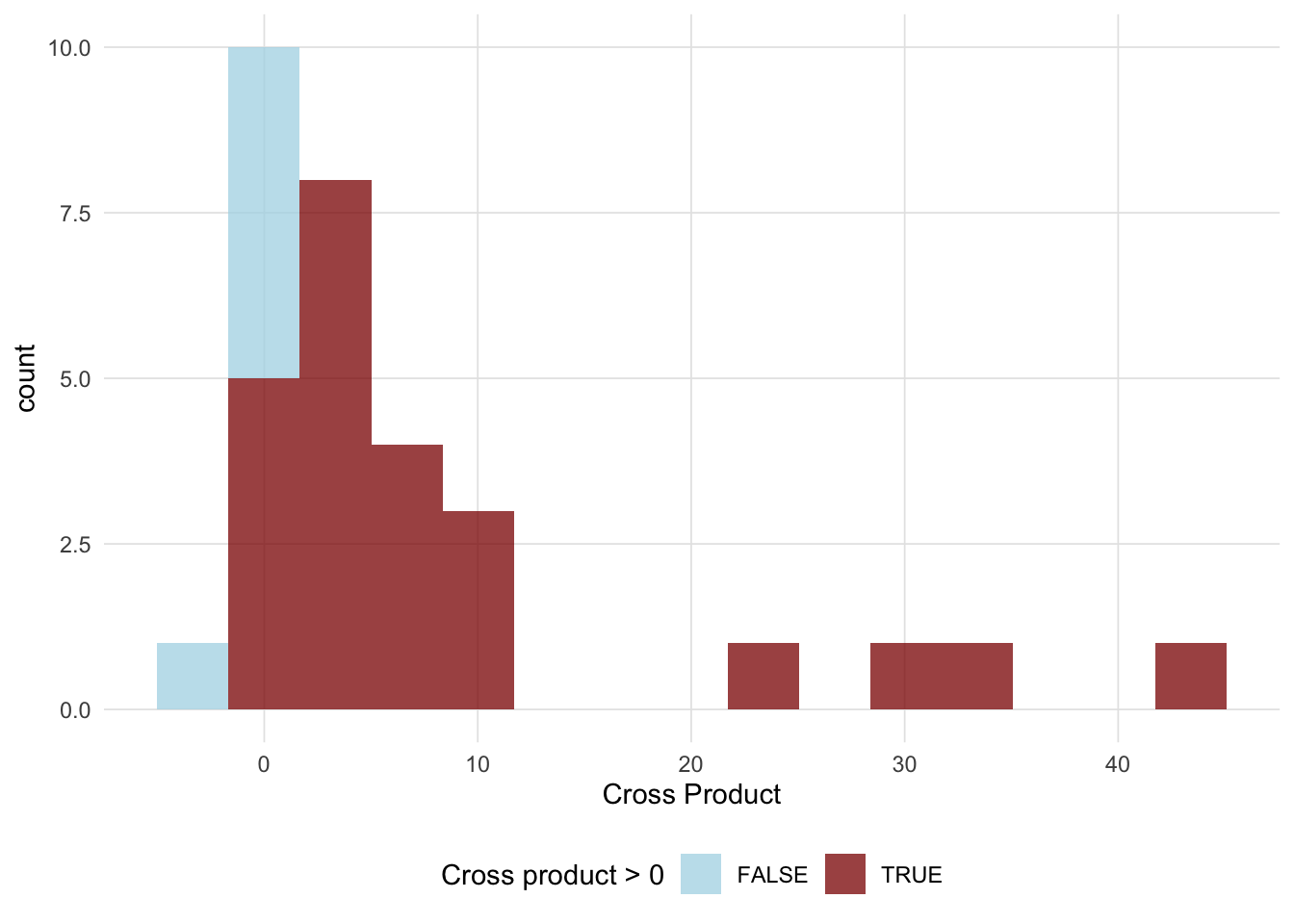
Figure 4.4 depicts all the cross products but shades the cross products that are positive in blue and cross products that are negative in red. As a result we can interpret the covariance as the ratio of the area of cross products for points in quadrants 1 and 3 to the area of the cross products for points in quadrants 2 and 4.
The last part of Equation 4.2 is the denominator where we average across all of the observations. If we wish to calculate the covariance for a population we divide my n, but for sample covariance we divide by n - 1. Substuting Equation 4.2 into Equation 4.1 we get the following:
\[{ r }_{ xy }=\frac { \frac { \sum _{ i=1 }^{ n }{ \left( { X }_{ i }-\overline { X } \right) \left( { Y }_{ i }-\overline { Y } \right) } }{ n-1 } }{ { s }_{ x }{ s }_{ y } } \tag{4.3}\]
The Shiny application allows you to play with all of the features that go into calculating correlation. Clicking on individual points will display the cross product.
This Shiny application can be run locally using the VisualStats::correlation_shiny() function.