This document outlines the various ways we could model dichotomous outcomes and why the log likelihood is the preferred approach. We will work through a small data set from Wikipedia that examines the relationship between the number of hours studied and passing an exam.
Show the code
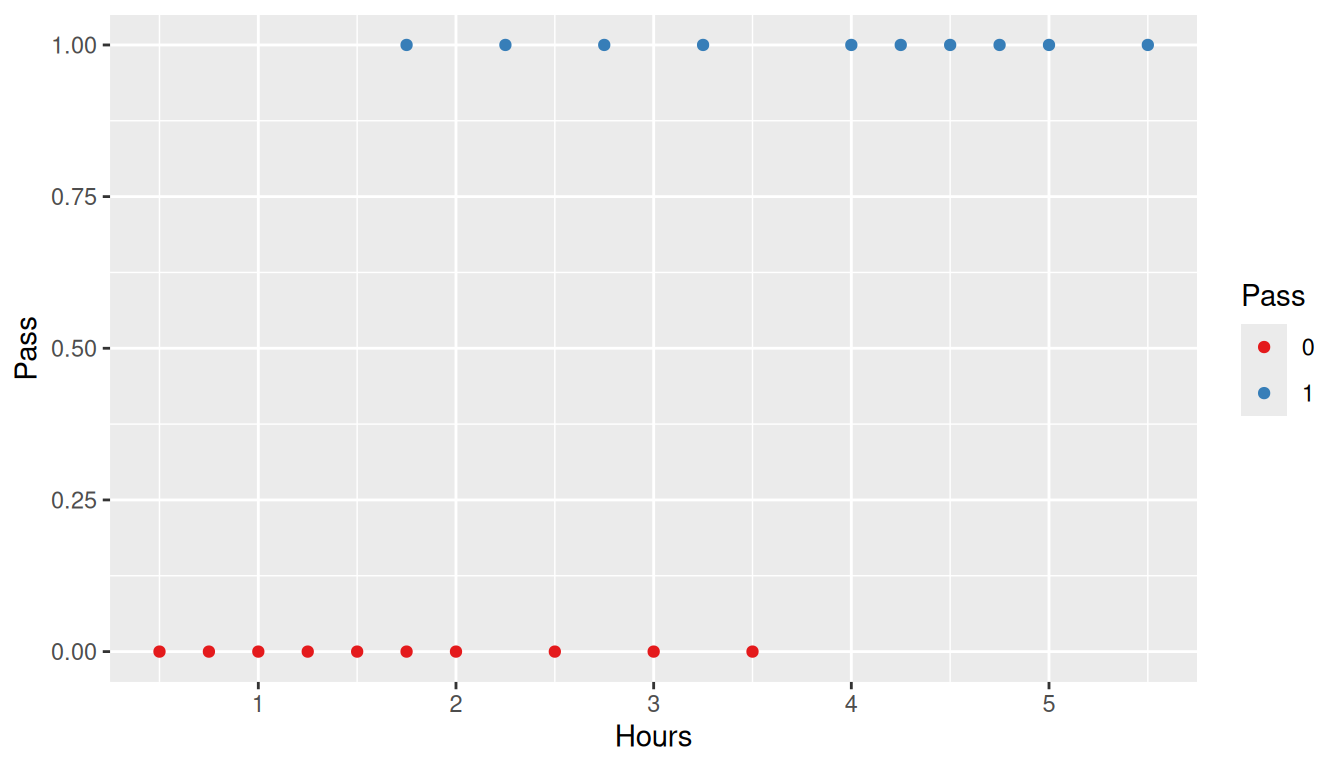
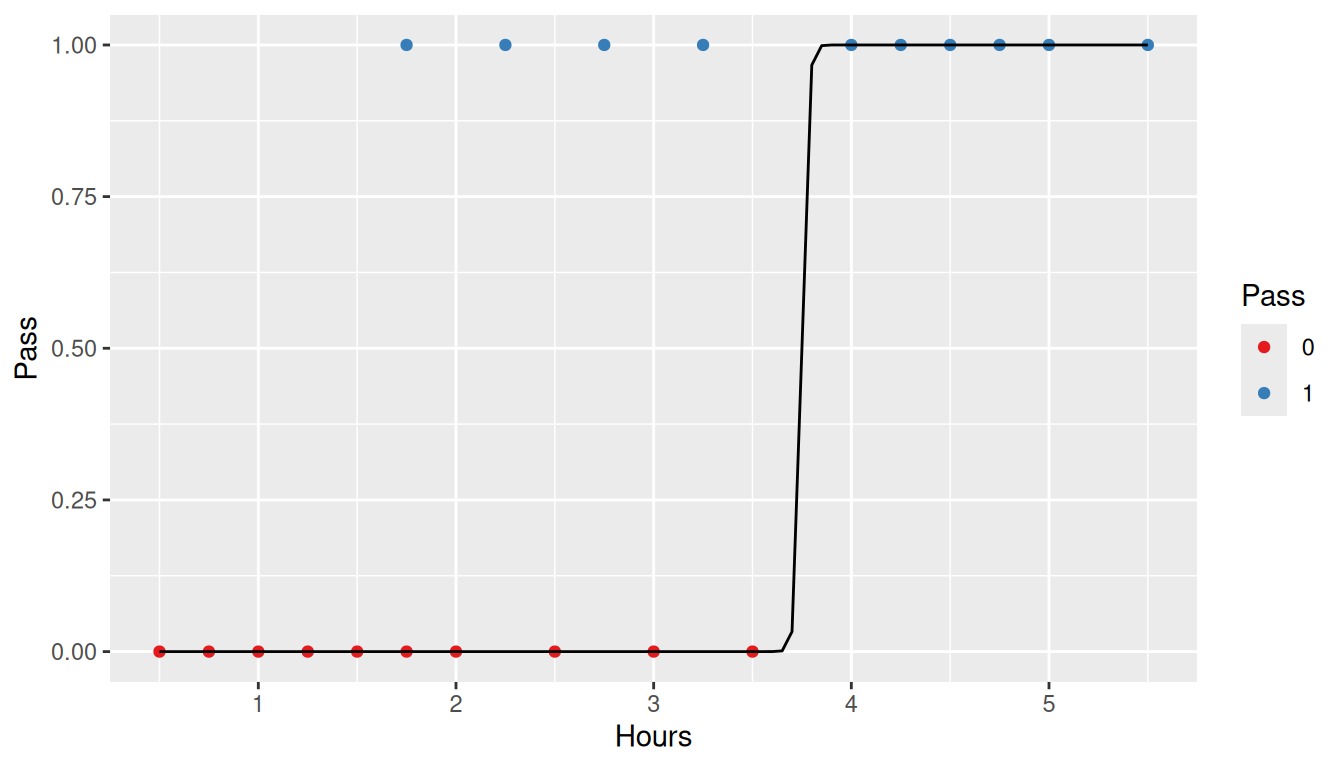
study <-data.frame(Hours=c(0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,2.50,2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50),Pass=c(0,0,0,0,0,0,1,0,1,0,1,0,1,0,1,1,1,1,1,1))ggplot(study, aes(x = Hours, y = Pass)) +geom_point(aes(color =factor(Pass))) +scale_color_brewer('Pass', type ='qual', palette =6)
11.1 Linear Regression
We will first consider simple linear regression.
Show the code
linear_regression <-lm(Pass ~ Hours, data = study)linear_regression
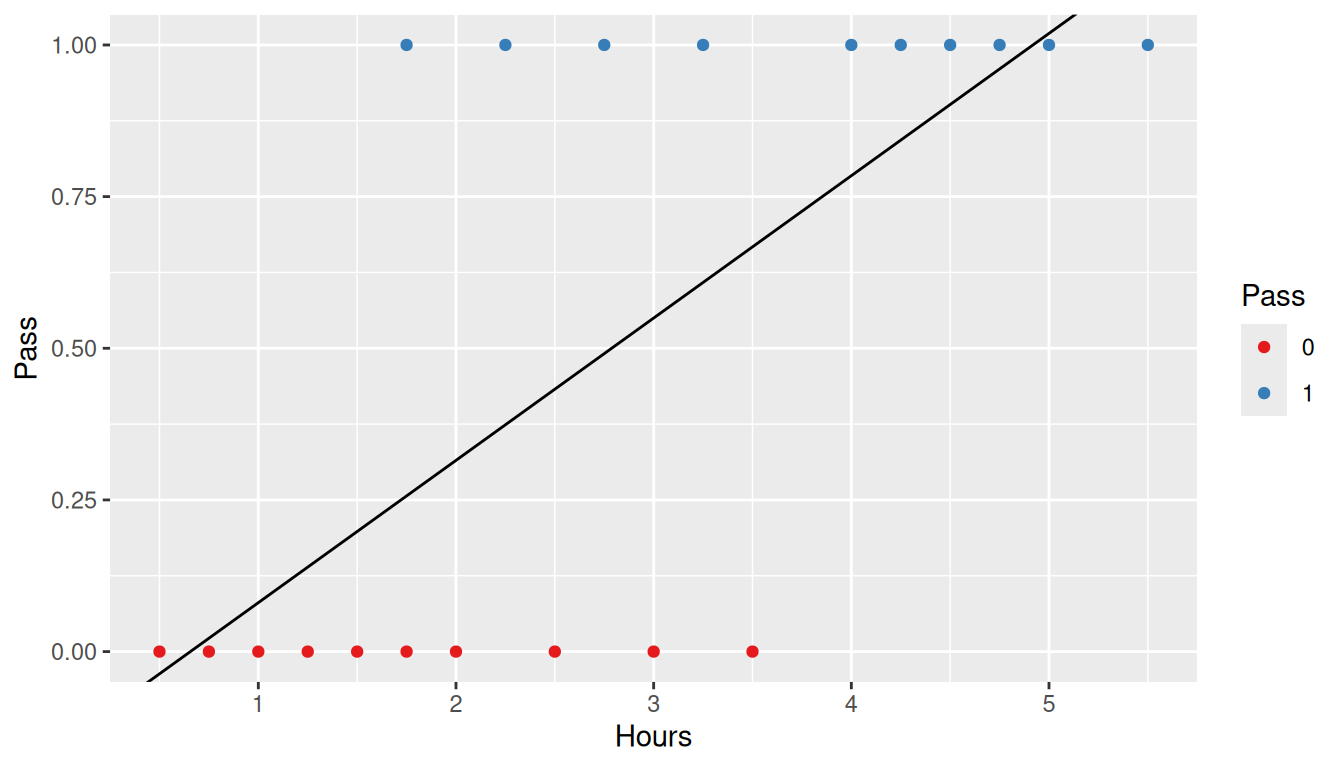
The resulting linear regression line is presented below.
Show the code
ggplot(study, aes(x = Hours, y = Pass)) +geom_point(aes(color =factor(Pass))) +geom_abline(slope = linear_regression$coefficients[2],intercept = linear_regression$coefficients[1]) +scale_color_brewer('Pass', type ='qual', palette =6)
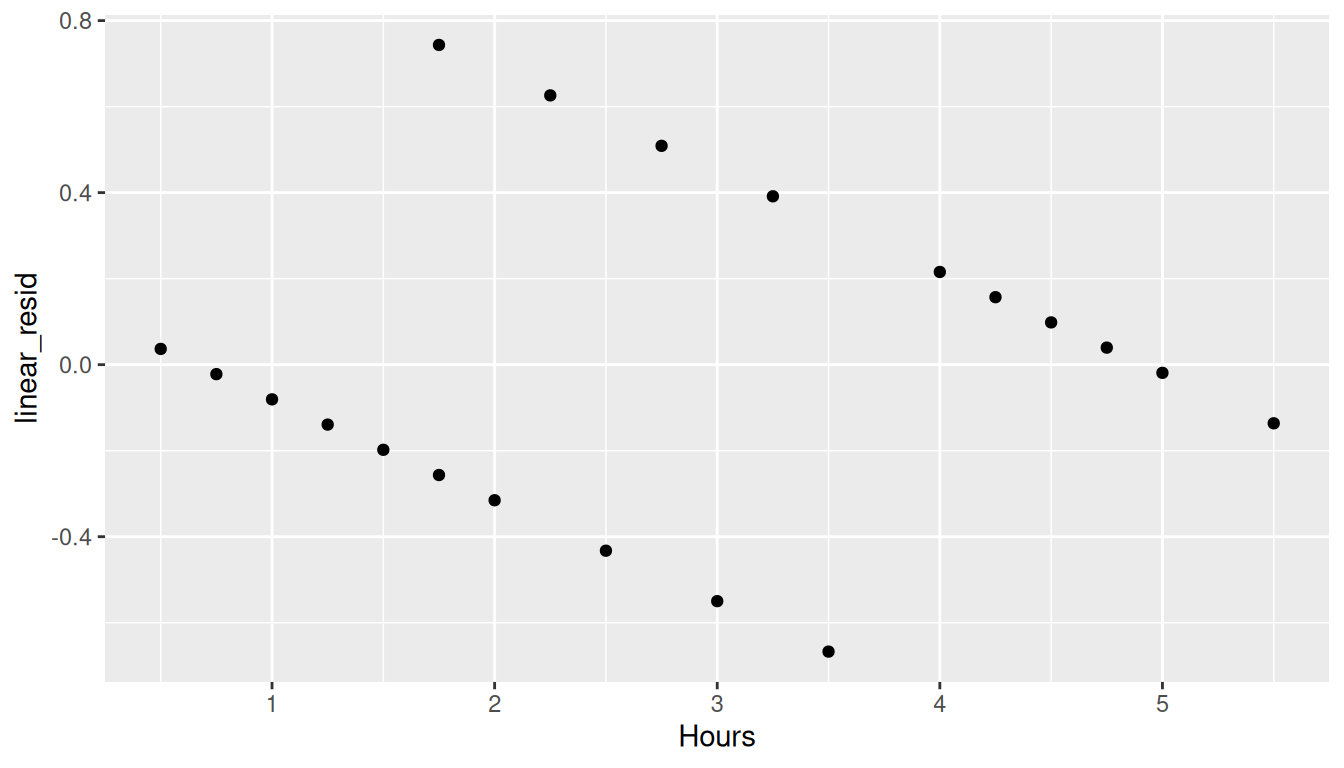
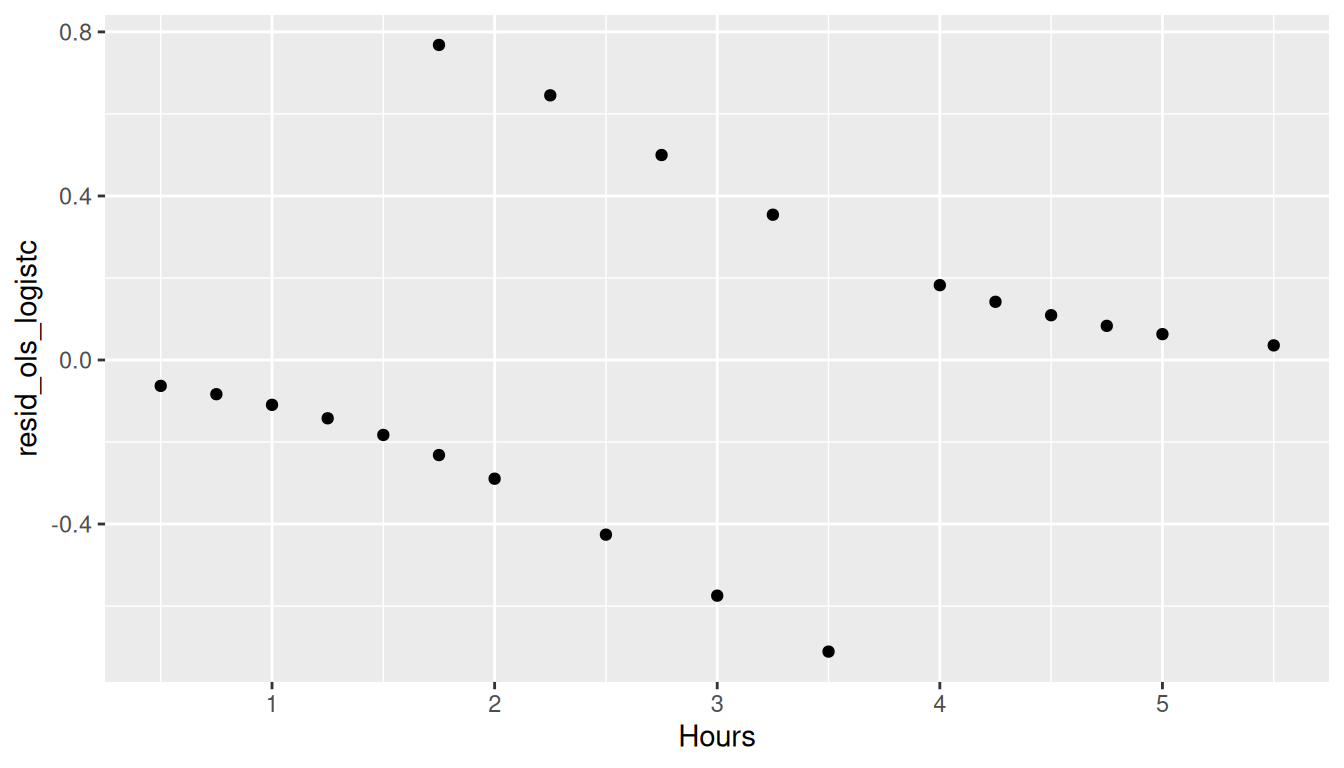
The \(R^2\) for this model is 0.48 which, on the surface, does not appear to be too bad. However, examining the residual plot shows that the homoscedasticity assumption of linear regression is clearly violated.
Show the code
study$linear_resid <-resid(linear_regression)ggplot(study, aes(x = Hours, y = linear_resid)) +geom_point()
As we proceed, we will want to estimate the parameters using a numeric optimizer. The optim function in R implements a number of routines that either minimize or maximize parameter estimates based upon the output of a function. For ordinary least squares, we wish to minimize the sum of squared residuals (RSS). The function below calculates the RSS for a given set of parameters (i.e. slope and intercept).
Show the code
ols_linear <-function(parameters, predictor, outcome) { a <- parameters[1] # Intercept b <- parameters[2] # beta coefficient predicted <- a + b * predictor residuals <- outcome - predicted ss <-sum(residuals^2)return(ss)}
To get the parameter estimates, we call the optim function with the ols_linear function defined above.
We see that the parameter estimates are the same as the lm function to several decimal places. For the rest of this document, we will use this approach to estimate parameter estimates and simply modify the metric we wish to optimize.
11.2 Minimize Residuals for the Logistic Function
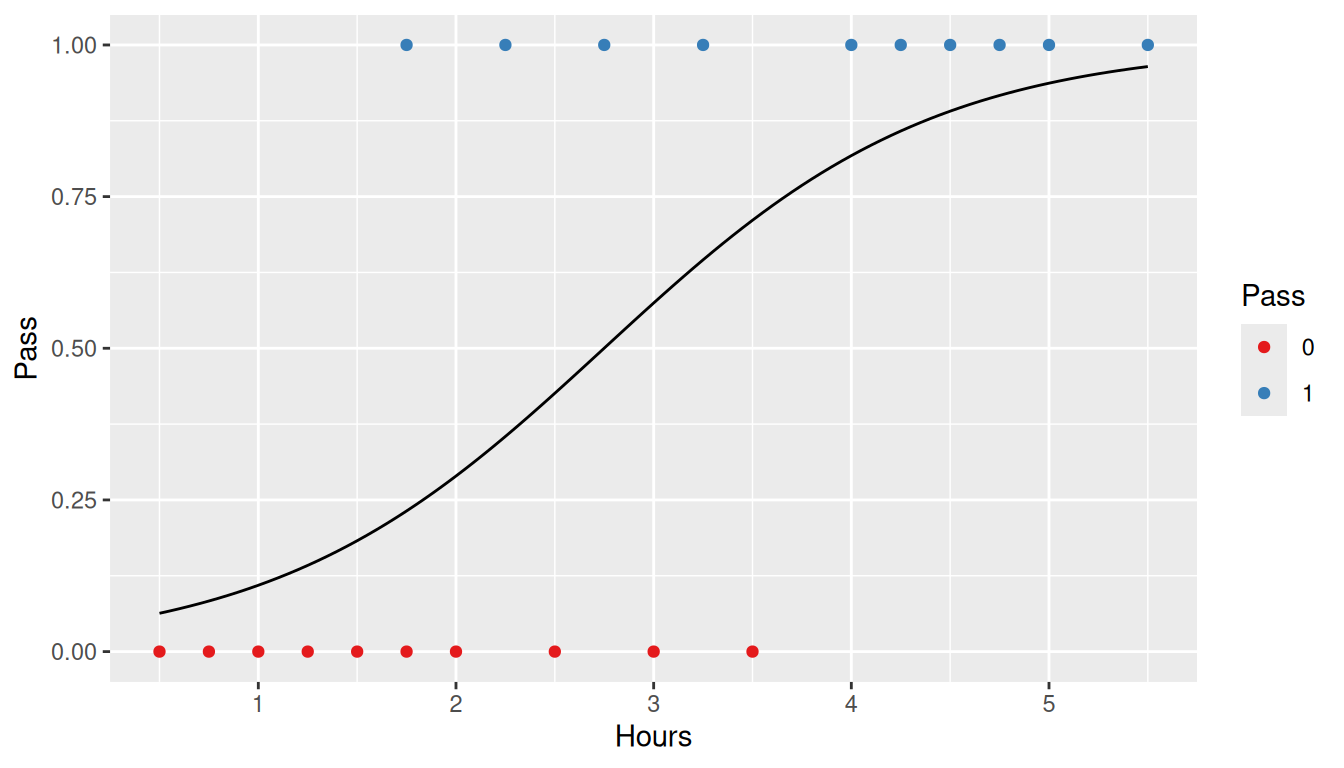
Since the relationship between hours studies and passing is not linear, we can try a non-linear method. The logistic curve is an S shape function which, on the surface, would appear to be a better approach.
Our first approach will be to minimize the sum of the absolute value of the residuals.
Show the code
min_abs_resid <-function(parameters, predictor, outcome) { a <- parameters[1] # Intercept b <- parameters[2] # beta coefficient p <-logit(predictor, a, b) resid <- outcome - preturn(sum(abs(resid)))}
Examining the resulting model shows that this approach is an overfit of the data. Next, let’s try minimizing the RSS using the logistic function.
Show the code
ols_logistic <-function(parameters, predictor, outcome) { a <- parameters[1] # Intercept b <- parameters[2] # beta coefficient p <-logit(predictor, a, b) resid <- outcome - preturn(sum(resid^2))}
And like above, the homoscedasticity assumption is violated.
11.3 Maximize Log Likelihood
The results of logit function can be interpreted as the likelihood of the outcome given the independent (predictor) variable. Instead of minimizing the residuals, defined above as the difference between the likelihood and observed outcome, we can minimize the log of the likelihood. Note that in the function below, we are using the log of 1 - likelihood (we’ll discuss why below).
Show the code
loglikelihood.binomial <-function(parameters, predictor, outcome) { a <- parameters[1] # Intercept b <- parameters[2] # beta coefficient p <-logit(predictor, a, b) ll <-sum( outcome *log(p) + (1- outcome) *log(1- p))return(ll)}
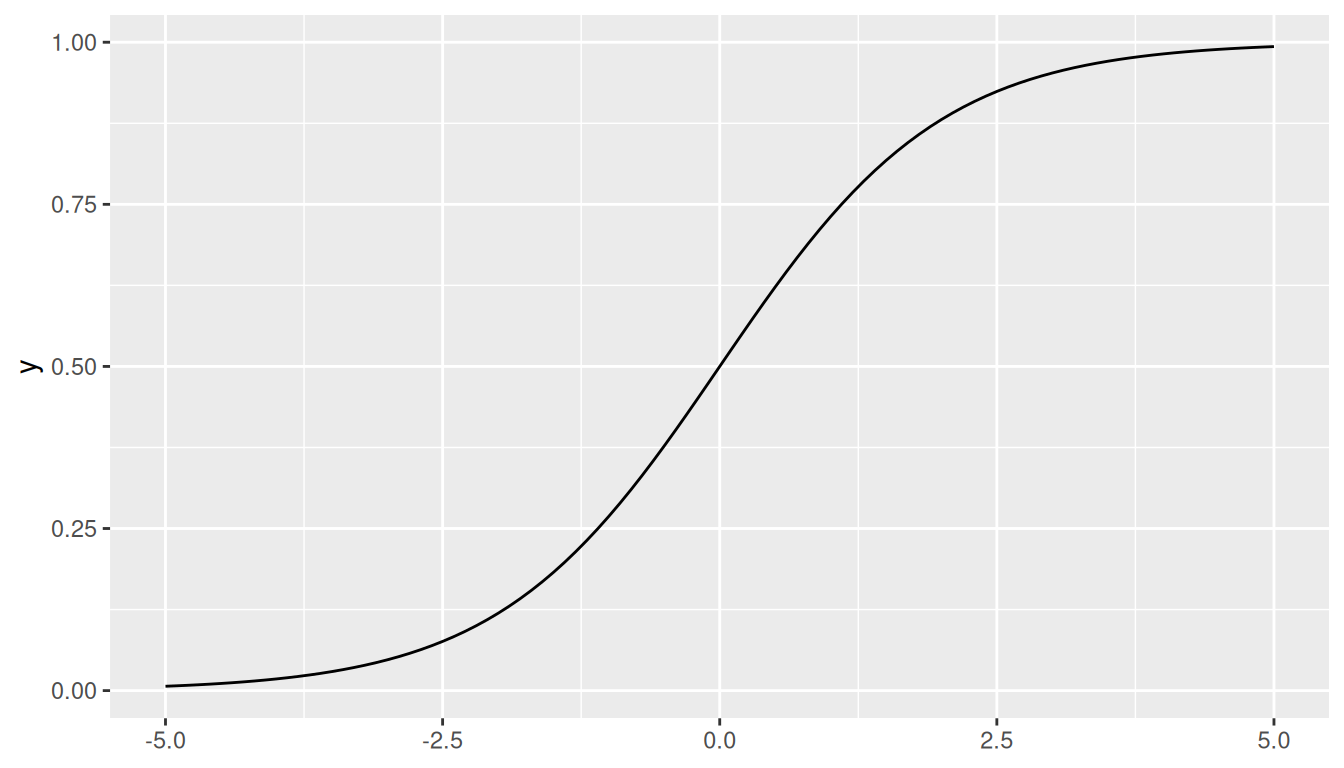
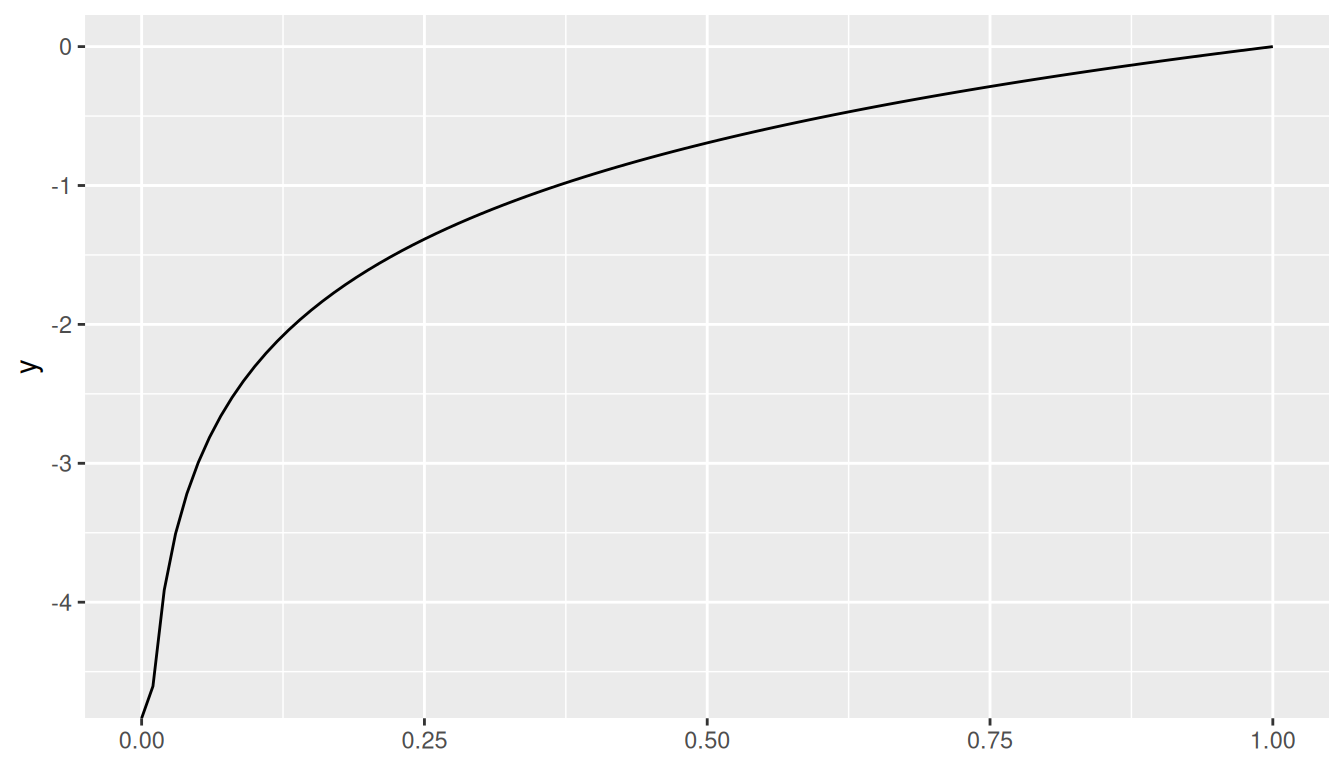
The log Function. Since we know our outcomes are either zero or one, and hence bounded by zero and one, then we are only considering values of log(x) between zero and one. The plot below shows that log(x) for all \(0 \leq 1x \leq 1\) is negative, going asymptotically to \(-\infty\) as x approaches zero.
Show the code
ggplot() +geom_function(fun = log) +xlim(0, 1)
Since \(log(1) = 0\), we want to reverse the likelihood, that is, we will take the \(log(1 - likelihood)\) so that smaller errors result in larger log-likelihood values.
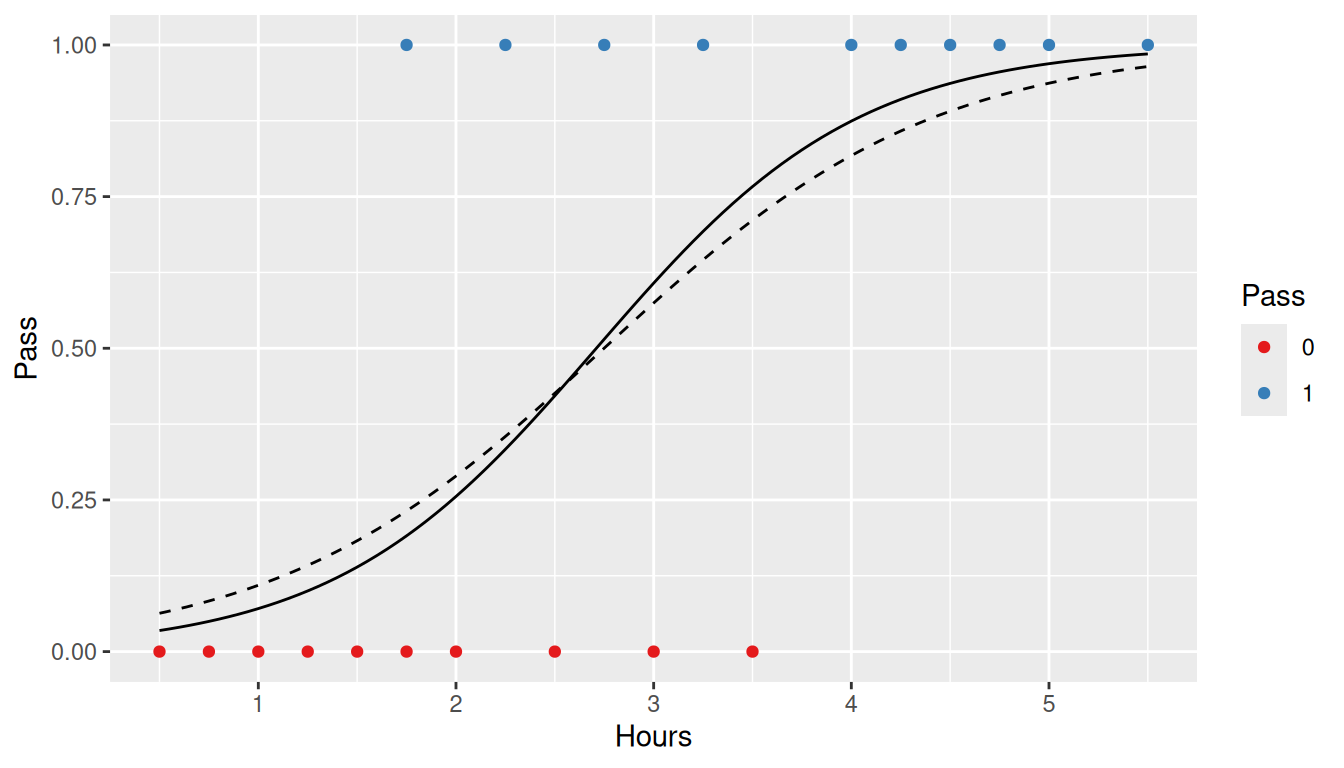
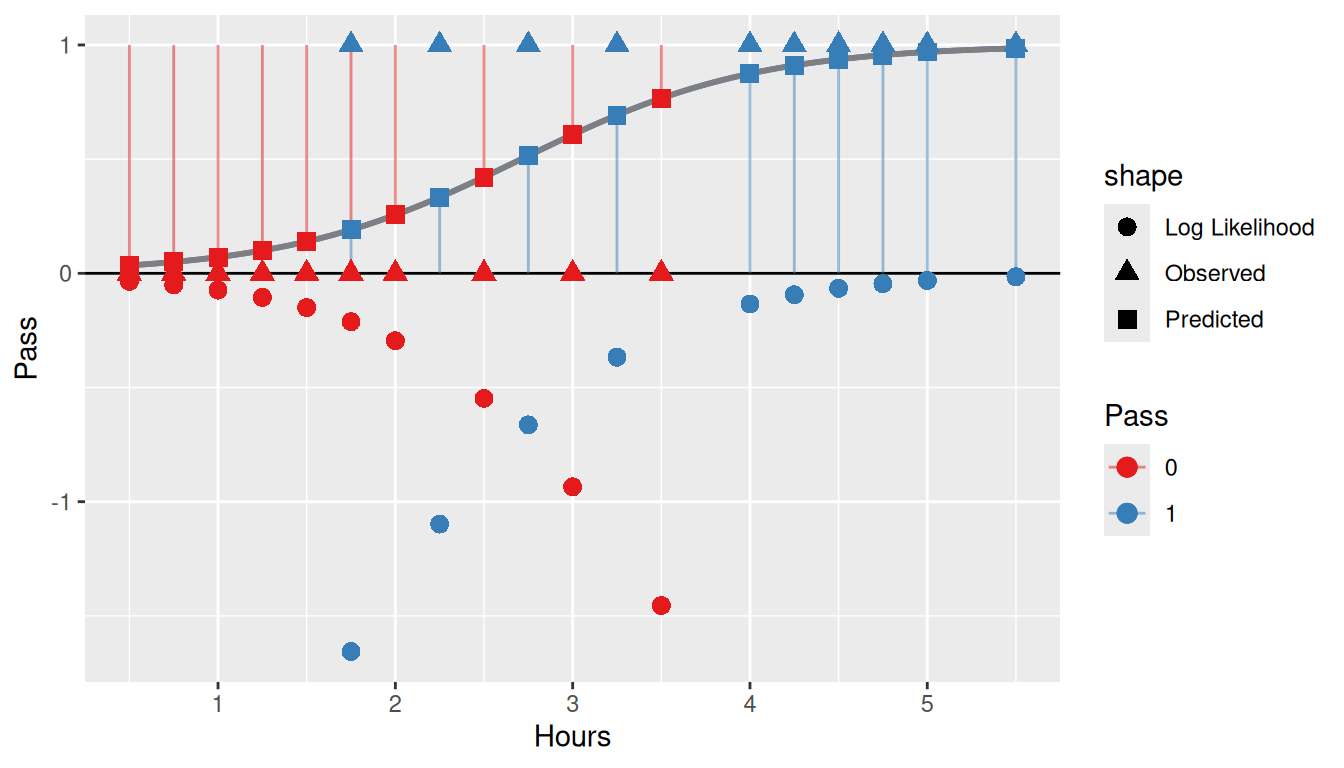
To put this all together, we will calculate the likelihood (i.e. predicted value using the logistic function), and the log-likelihood (what we maximized). The plot shows the observed values (as triangles), predicted values (as squares), and the log-likelihood (as circles). The lines represent the values we are taking the log of. That is, if Pass == 0, then we take the log of 1 - likelihood; conversely if Pass == 1 then we take the log of the likelihood. The circles below the line y = 0 are the log values. As can be seen, since they are all negative we wish to maximize the sum of their values to achieve the best fit.
ggplot(data = study, aes(x = Hours, y = Pass)) +geom_smooth(method ='glm', formula = y ~ x,method.args =list(family=binomial(link='logit')), se =FALSE, alpha =0.2) +geom_hline(yintercept =0) +geom_function(fun = logit, color ='grey50', size =1,args =list(beta0 = optim_binomial$par[1], beta1 = optim_binomial$par[2])) +geom_segment(aes(xend = Hours, y =1- Pass, yend = likelihood, color =factor(Pass)), alpha =0.5) +geom_point(aes(y = likelihood, color =factor(Pass), shape ='Predicted'), size =3) +geom_point(aes(color =factor(Pass), shape ='Observed'), size =3) +geom_point(aes(y = log_likelihood, color =factor(Pass), shape ='Log Likelihood'), size =3) +scale_color_brewer('Pass', type ='qual', palette =6)
11.4 Assumptions
Although maximizing the log-likelihood provides a result similar to minimizing the sum of squared residuals using the logistic function, the log-likelihood doesn’t rely on the assumptions of residuals OLS does. Namely:
There is no assumption of linearity between the dependent and independent variables.
Homoscedasticity (constant variance) is not for logistic regression (but is for linear regression).
The residuals do not have to be normally distributed.
There is an assumption of linearity between the independent variable(s) and the log-odds.
Show the code
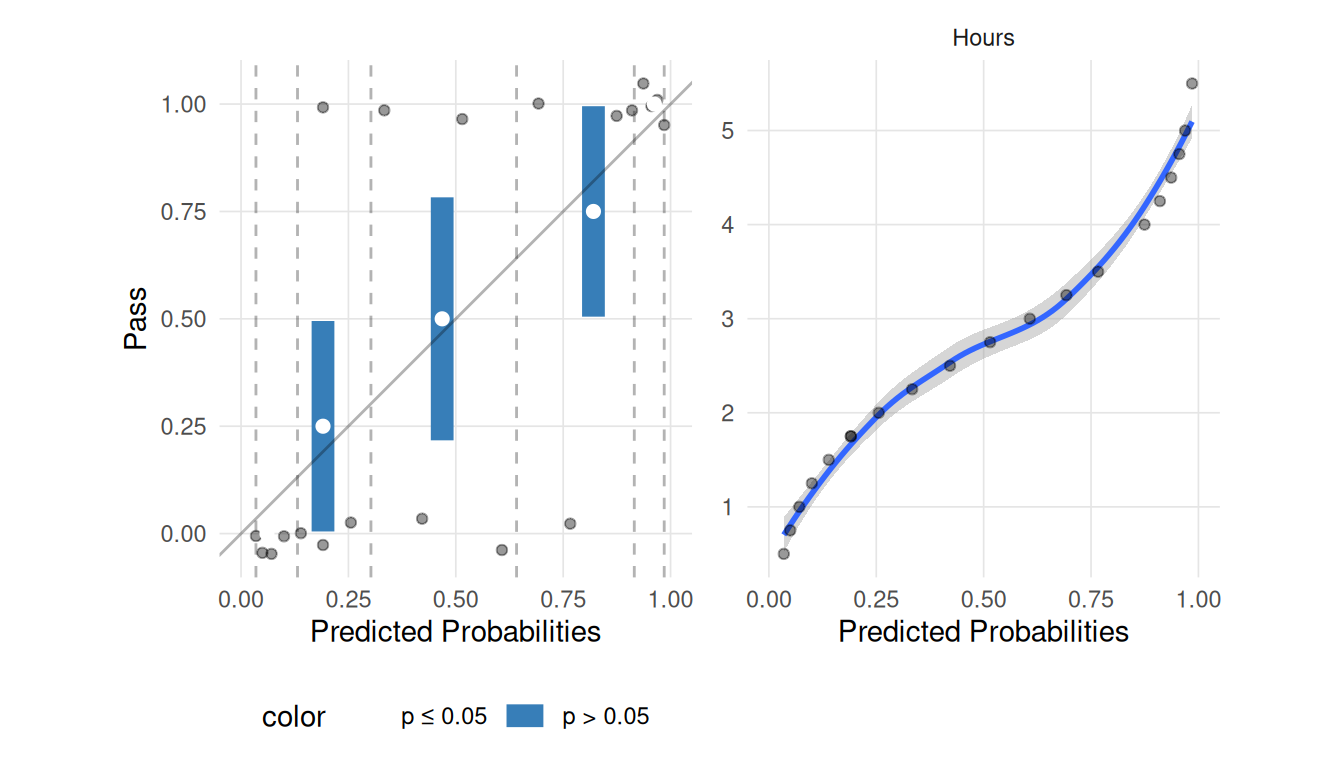
lr.out <-glm(Pass ~ Hours, data = study, family =binomial(link='logit'))plot_linear_assumption_check(lr.out, n_groups =5)
The Box-Tidewell test can be used to check for linearity between the predictor(s) and the logit. This is implemented in the car package in R. We are looking for a non-significant value here.
Show the code
study$logodds <- lr.out$linear.predictorscar::boxTidwell(logodds ~ Hours, data = study) # Looking for a non-significant p-value